AWS Lambda: How to create zip from files
nb: There is a more detailed second part of this post available here:
GHOST_URL/2017/06/06/aws-lambda-part-ii-how-to-create-zip-from-files/
Hi,
It has been a pain recently I have been personally involved into many things, and I did not manage to deal with my blog and writing about stuff that cares to me. However here it comes and I will now today talk about a subject I faced recently while programming.
What is AWS Lambda
AWS stand for Amazon Web Services this is a hosting company ran by Amazon were there is a set of services for developers. You’ll be able to do pretty much everything on it. AWS is large, huge and has many services. While working I’m using few of them such as:
- DynamoDB - A managed noSQL database
- API Gateway - A set for building APIs
- S3 - Storage spaces
- Lambda - A FaaS Function as a Service
- EC2 instance/computation
- SNS Simple Notification System
- SQS Simple Queuing System
- Codepipeline/CodeBuild/CodeDeploy set of tools in order to pipe, compile, deploy easily and automatically programs/configurations pieces of code or more
Today we are talking about AWS Lambda

AWS Lambda is a FaaS, Function as a Service, Run Code, Not Servers. Actually it means you will only have to care about your development, environment configurations then AWS will take care of the rest (ressources/scaling and everything)..
Serverless
In order to work with AWS Lambda, I am using the AWS Framework Serverless.
Pretty simple to install:
npm install serverless -g
serverless create --template aws-nodejs
serverless deploy
Once you are familiar with Serverless you’ll be able to run function into AWS Lambda.
Serverless is an environment where you’ll wrap your Node.js code into it and it works with events. You could pass to your program many types of events. Events are json based you pass a json object as parameter then parse it and run your program.
The advantage of this is that you can entirely customize your inputs, configs and parameters given to a serverless program. Moreover all other AWS service are event based and they can be emitted depending on various type of event. Meaning you can trigger a Lambda from other service from AWS and make them work together.
For example you can set events on S3 event such as POST/PUT/CREATE-OBJECT etc… Same thing for DynamoDB, when you are INSERTING/REMOVING/MODIFIYNG a row then it trigger an event and you can easily link this to a Lambda. It’s POWERFULL.
Zip Files what’s the deal
Ok, first time I needed to make this the schema was easy. Actually there is many ways to do so. The easiest pattern that cames to my mind was the following one.
-
Fetch files you want to make a zip with and store them into a folder (optional) or at least store them on the same location eg:
/tmpdirectory (nb: when you are working with AWS Lambda you will see, the only space you are allow to write something is into the/tmpdirectory/) -
Files are now gathered take your favourite zip wrapper and zip your directory/files
-
Upload your file to a bucket in S3
That’s it, it’s simple.
I have few problems with this solutions:
- I am storing files locally whereas those files are already stored into a bucket. It could be better if we can save this space up, and directly give the S3 files a streams into our zip wrapper
- Depending on the space available on the AWS Lambda instance and the number of files you want to zip you may got a lack of space on your disk space
/tmpdirectory, and your zip lambda will fail - Moreover I notice something very bad about AWS Lambda system architecture it seems that sometimes the same machine could be used from different invocations. Meaning if you are not cleaning up your
/tmpdirectory after work, you might get the previous issue. Even if nothing has been written on the disk you can get aENOSPCerror. Meaning disk is full or has not enough space.
AWS Lambda limitations
Ressource
Default Limit
Ephemeral disk capacity (“/tmp” space)
512 MB
Number of file descriptors
1,024
Number of processes and threads (combined total)
1,024
Maximum execution duration per request
300 seconds
Invoke request body payload size (RequestResponse)
6 MB
Invoke request body payload size (Event)
128 K
Invoke response body payload size (RequestResponse)
6 MB
Source: http://docs.aws.amazon.com/lambda/latest/dg/limits.html
According to the values above two things are important concerning our needs.
-
The ephemeral disk capacity
If you deal with files/directory larger than 512Mb or even if the output of your zip if bigger than 512Mb you will get into trouble -
Maximum execution duration per request
If your zip process handle too much files and need more than 5 minutes the AWS Lambda does not suit your needs you will be forced to use something else
I found a temporary solution that will pretty avoid few AWS limitations, it supposed to scale properly but it will have for sure some limitations. Nevertheless at least for what I was looking for it was right.
Zip is actually a transformed stream
In order to achieve the zip process I use the following npm modules:
The idea of zipping stuff is easy and nothing more than this:
- A readStream where the source called S
- A transformation stream our zip wrapper called T
- A writeStream the output zip file called O
Then you pipe the 3 streams above and you will get a zip.
S => T => O Where O is now a zip file of S.
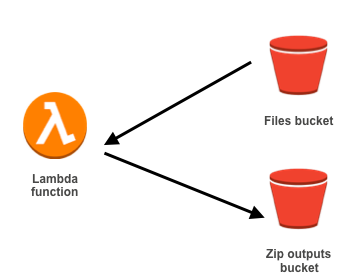
Ok this looks good to me but we can improve it. Generally writeStream is about local file, meaning you will have to store the zip output locally before sending it out into a bucket or elsewhere, but the 512Mb disk space limit is still here. How to deal with it?
I turned a s3 putObject method into a special writeStream, which will directly put the output into another bucket.
The idea behind this is to never store locally anything.
- You fetch your files from the bucket as a stream
- You pipe this stream to your transform function (zip wrapper)
- You pipe the zip wrapper output as a S3 stream directly to your output bucket
Perhaps I did not dig enough but I did not manage to do this natively from the s3 aws-sdk in Node.js.
I used s3-upload-stream this let you to make a writebale stream in order to put your output directly into the bucket.
As far as I know this a working solution. Again the remaining issue will be the execution time limit from Lambda. Even if you can avoid some limitations from AWS Lambda you will not be able to go over 5 minutes of computation while doing a zip from resources. Also I did not talk about it, but you have to keep on eye on your memory usage. I did not monitored this since I did not face any problem with it, but stream can be memory consuming (if you are buffering too much data or if the stream is entirely stored into memory I am not sure about how things are handled on that side ), and you should take care of it.
Get notified when I publish something new. No spam, unsubscribe anytime.